
Soundsocial
Description as a Tweet:
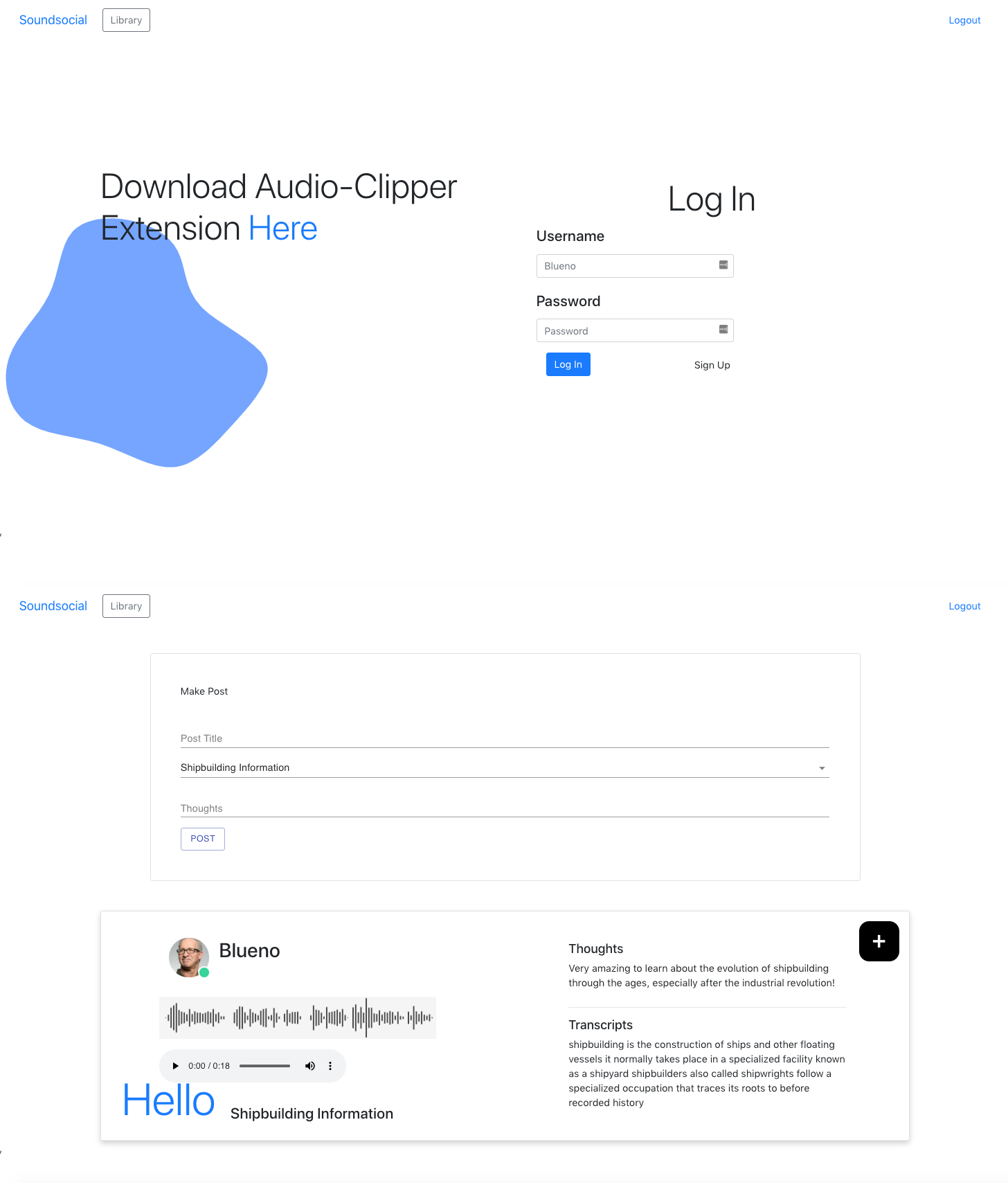
Soundsocial is a personal knowledge management & audio-based social media tool to help users find, curate, and share all forms of spoken text audio such as Podcasts, YouTube videos, or Online Tutorials.
Find us at: http://soundsocial.online/
Inspiration:
All three of us are eager consumers of podcasts, and we have yet to find an effective way to take notes and share insightful information which resonates with us. We wanted the ability to, with one click of a button, store the contents of a podcast (YouTube video, or tutorial) both in audio and in text (transcription) so we could revisit it later. Because of this, we decided to create soundsocial.online, a platform to curate, share, and discover new sources of informational spoken audio online.
In addition to the capturing, and transcription of audio, soundsocial gives users the ability to publicly share clips of audio (along with their thoughts). Similar to websites like Goodreads or TikTok, we view soundsocial as being a place where people can come to discover intellectual conversations, deep philosophical discussions, and more.
What it does:
There are two ways to use our project: find and curate a personal knowledge library of spoken text (with our in-built transcription) and/or share your thoughts on podcasts, YouTube videos, and tutorials publicly with the world.
How we built it:
We built our front end portal and social sharing platform in React, HTML/CSS/Javascript. We used Redux for state management as well as UI design libraries such as Material UI, TailwindCSS, and React Bootstrap.
Our backend was written in Python and Flask. We used a MongoDB database for storing user information such as usernames/hashed passwords, posts, and audio clip meta-data. We stored the waveform (audio) files as well as the generated waveform graphic on Google Cloud Storage.
We created a small Linux utility extension to record system-level audio using GTK, Python, and FFMPEG. This extension is useful for grabbing audio clips and sending them to our Flask backend where they are transcribed (using a pre-built speech-text ML model), and stored (in google cloud) along with a generated image of the waveform plot.
Technologies we used:
- HTML/CSS
- Javascript
- React
- Python
- Flask
- AI/Machine Learning
Challenges we ran into:
The biggest challenge by far was creating the utility extension to grab system audio and send it to our backend (to be transcribed and added to a user’s library).
We built multiple helper applications before settling on a Linux app using GTK & Python to capture and store user audio. We first tried to create a MacOS menu bar app with Python, PyAudio, and rumps but struggled to get by a restriction MacOS had on preventing applications from recording system audio. We then tried to pivot by creating a chrome extension, almost completing it but struggling to send the audio captured to our Flask backend - due to the fact that Google Chrome places restrictions on extensions writing to the filesystem (we needed to create a temp file to send back in our form-data). We finally settled on creating a Linux app in GTK & Python, however we’re going to continue working on our MacOS and Chrome Extension to try and find workarounds to the problems we faced.
Accomplishments we're proud of:
We’re proud of our backend processing pipeline and the way in which we leveraged MongoDB and Google Storage to store our audio clips. The transcription model we used worked nicely along with the waveform image generation script to efficiently process clips as they came in and assign them to a given user’s library of content. Lastly, we're proud of our ability to adapt to issues we faced with with the helper audio capture utility.
What we've learned:
Because we tried so many different solutions for our audio clipper, we gained exposure working with MacOS Menu Applications, Chrome Extensions, Electron Apps, and Python libraries like GTK.
Additionally, we leveled up our skills working with Google Cloud & React/Flask.
What's next:
We want to fix the issues we were facing with our Chrome Extension and publish it to allow an additional way to add content to your audio library.
Built with:
We deployed our front end portal with Netlify and hosted our website using a domain purchased from Domain [dot] com.
We deployed our backend Flask server on a Google Cloud Instance, and used a Google Storage bucket to store user submitted audio clips. We used MongoDB Cloud Atlas for our database.
Prizes we're going for:
- Best Documentation
- Best Web Hack
- Best Domain Name
- Best Machine Learning Hack
- Best Use of Google Cloud
Team Members
Kevin Hsu
Michael Donoso