
Scribary
Description as a Tweet:
A note sharing platform to combat the lower quality learning of the remote learning era. Check out our demo at https://scribary.herokuapp.com and Github at https://github.com/mathewjhan/scribary!
Inspiration:
A common struggle in this remote learning era of university is staying focused during lectures. Issues with internet connections prevent students from watching lectures consistently. Issues with time zones prevent students from attending synchronous lectures. Even subtle issues such as the sound compression of a video lecture versus the engaging reverberations of a live lecture hall cause students to have difficulty paying attention to lecture. Through all the inconveniences of remote learning, _it is clear that the quality of learning has gone down._ During an in-person semester, students learn from classroom discussions, study groups, and office hours. But with no proper classroom environment, many students lose the motivation to stay engaged with course material, and as a result, take lower quality notes.
With time zones and the internet becoming a limiting factor of remote learning, _the BEST and most CONSISTENT way to learn is through the use of quality notes_, which are concise and small in size. However, with all the distractions and nuances of live lecture, it is also difficult to take good notes and sometimes professors don't share the best notes to study off of. Fortunately, over the years students accumulate great amounts of notes that simply end up rotting away on their hard drives. These notes can be especially useful during this time of stymied learning. As good notes are integral for learning the topic, we wanted to alleviate students’ stresses regarding this by creating a way for students to share notes with each other—that is, a library of notes for scribes—a Scribary!
What it does:
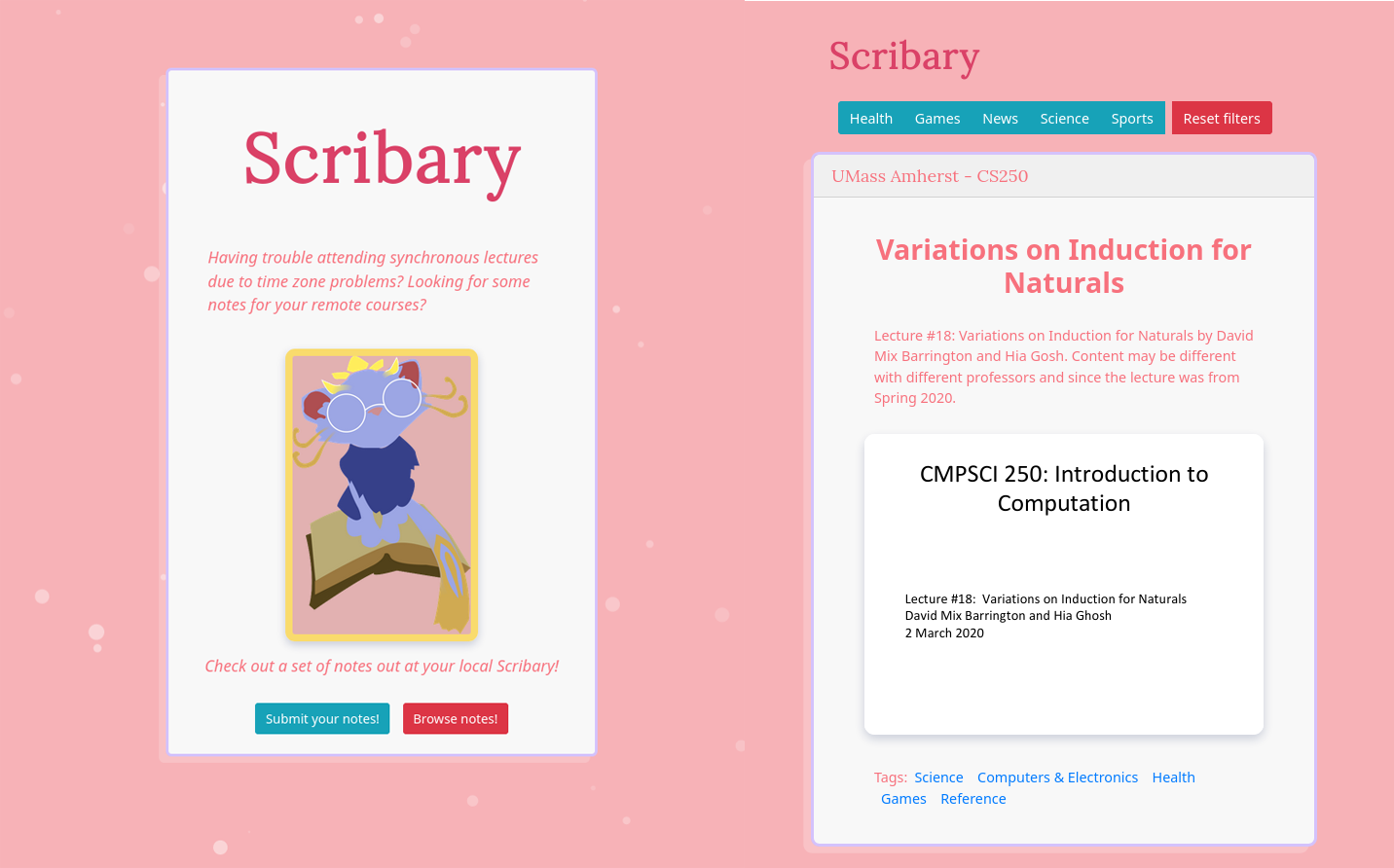
With the importance of notes in mind, we created Scribary, an online platform to improve the note-taking experience. Students can upload notes with descriptors such as title course, affiliated university, and course description. Each file upload is then parsed for context using Google Cloud's NLP machine learning API and assigned with relevant category tags, which can later be used by Scribary users to filter results. In the frontend, once a Scribary user finds notes that are relevant to what they want to learn, the file can be directly accessed with one click, allowing a streamlined experience to find the exact notes that they need.
How we built it:
We built the frontend with React, backend with Python, and connected the two through Flask. Files are stored in an AWS S3 bucket and relevant post information in a Datastax Astra database. Each entry of the database corresponds a single upload, whose hash is the primary key and whose other columns store relevant post data. With the help of Google Cloud’s Natural Language API, we predicted tags for each upload and determined relevant categories based on a confidence threshold. These predictions are stored in our database.
Technologies we used:
- HTML/CSS
- Javascript
- Node.js
- React
- Python
- Flask
- AI/Machine Learning
- Misc
Challenges we ran into:
One of our greatest difficulties was working with Datastax Astra. Due to our lack of experience working with Cassandra, we had difficulty figuring out how their REST query API worked. After hours of reading documentation, we were finally able to create functions that effectively searched the database. Another challenge we came across was linking the backend and frontend. Because some of the data sent over from the frontend was in a complex format, we had to figure out how to correctly serialize the data so that it would be interpreted correctly in the backend.
Accomplishments we're proud of:
Michael: I’m proud of designing my first web application at a hackathon. Most of my past experience at past hackathons was in embedded systems, so it was a nice change to work on web development!
Maggie: I’m proud of attending my first hackathon!
Mathew: I'm proud that we were able to complete a working product. When we first started, I thought there was little chance that we would actually create something functional, but we ended up grinding and finishing.
What we've learned:
Mathew: I learned a lot about practices in fetching data. Since the data we needed to POST was relatively complex, I had to perform a lot of data manipulation to get it to work.
Maggie: This was my first hackathon, so I learned a lot about how hackathons work, and was also given a basic introduction to machine learning through Google Cloud’s Natural Language API.
Michael: I learned about how to build a full stack web application. Setting up communication between React, Flask, AWS, and Datastax Astra was one of the most difficult parts of the project for us, and I learned a lot from it.
What's next:
There is so much that can be improved with our idea. In the future, we hope to add search functionality, smarter context creation, and support for other file extensions. In addition, we would like to expand our product to not only notes, but learning resources with student crowdsourced categories to allow students to easily narrow down and share resources with each other.
Built with:
We used VSCode as our main editor due to its convenient liveshare feature. In addition, we used git as our version control tool, React as our frontend, Flask as our backend, AWS s3 buckets/Datastax Astra for data storage, Google Cloud NLP API for machine learning context aware tag generation, PyPDF2 for PDF manipulation, and an assortment of other misc packages.
Prizes we're going for:
- Best Documentation
- Best Venture Pitch
- Best Web Hack
- Best Machine Learning Hack
- Best Beginner Software Hack
- Best Beginner Web Hack
- Best Use of DataStax Astra
- Best Use of Google Cloud
Team Members
Maggie Yu
Michael Ren